Regular Directions
- Download your Transcription from the Job Details page. The filename format is currently asrOutput.json.
- That’s easy. Done.
- Run the transcript.py program on the downloaded file, i.e. python ./transcript.py asrOutput.json
- I’ve
installed Python 3.11, and I ran the script “python ./transcript.py
asrOutput.json”
The result is a Syntax error (image).
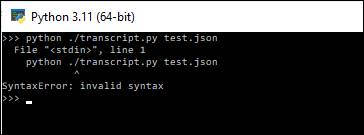
Image 1 - Results will be written in your current working directory as [FILENAME]-transcript.txt
Per results of step 2, I had no results.
S3/Lambda Directions
- Probably worth checking your lambda Memory/Execution time settings, depending on the size of the files you'll work with. I like ~256MB and ~15 seconds for general use.
- Where in AWS is that? I did a search, but didn’t receive that as a search result.
- Create an S3 bucket with two folders; input/ and output/
- Easy. Done (Image 7, below).
- Create a Lambda function that triggers on CreateObject in input/ (Triggers section of the UI)
- How
do you create Lambda functions?
The only Lambda options are to create “Object Lambda Access Points”? (image 2 below).
Note: I did this, but when I load asrOutput.json into the “input/” folder (step 1 above), nothing happens.
NOTE: If “Object Lambda Access Points” isn’t how to create a Lambda Function, you can stop here and avoid reviewing the screen shots below.
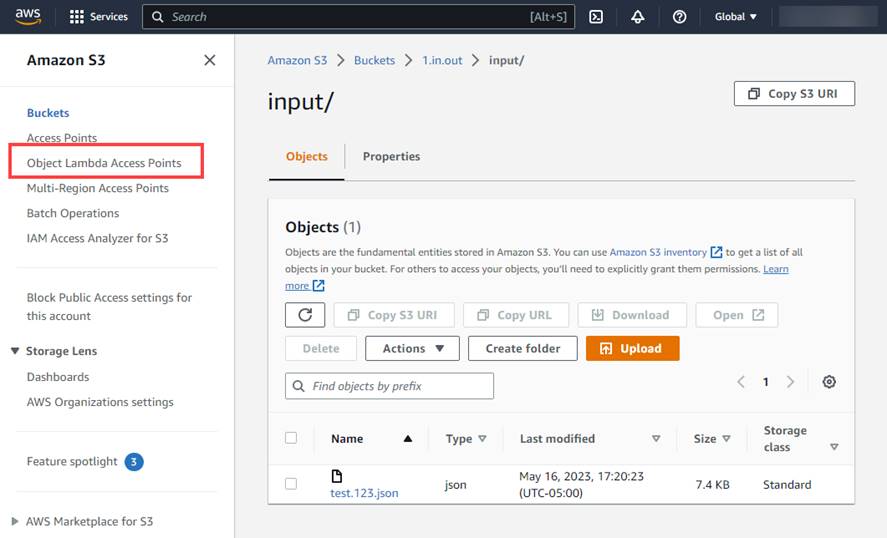
Image 2
- Clicking “Object Lambda . . “ navigates to “Object Lambda Access Points”, with 2 buttons titled “Create Object Lambda Access Points” (below)
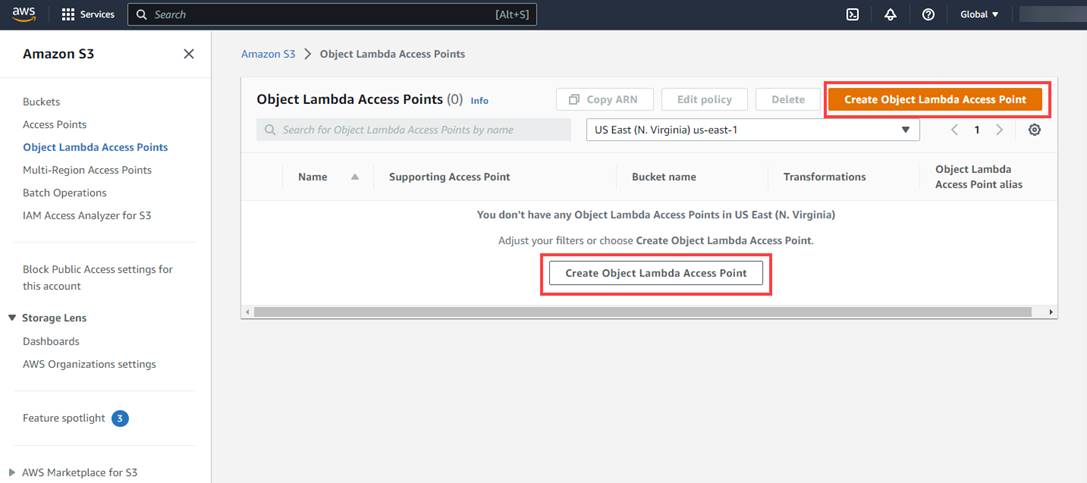
Image 3
3. Which navigates to “Create Object Lambda Access Point”
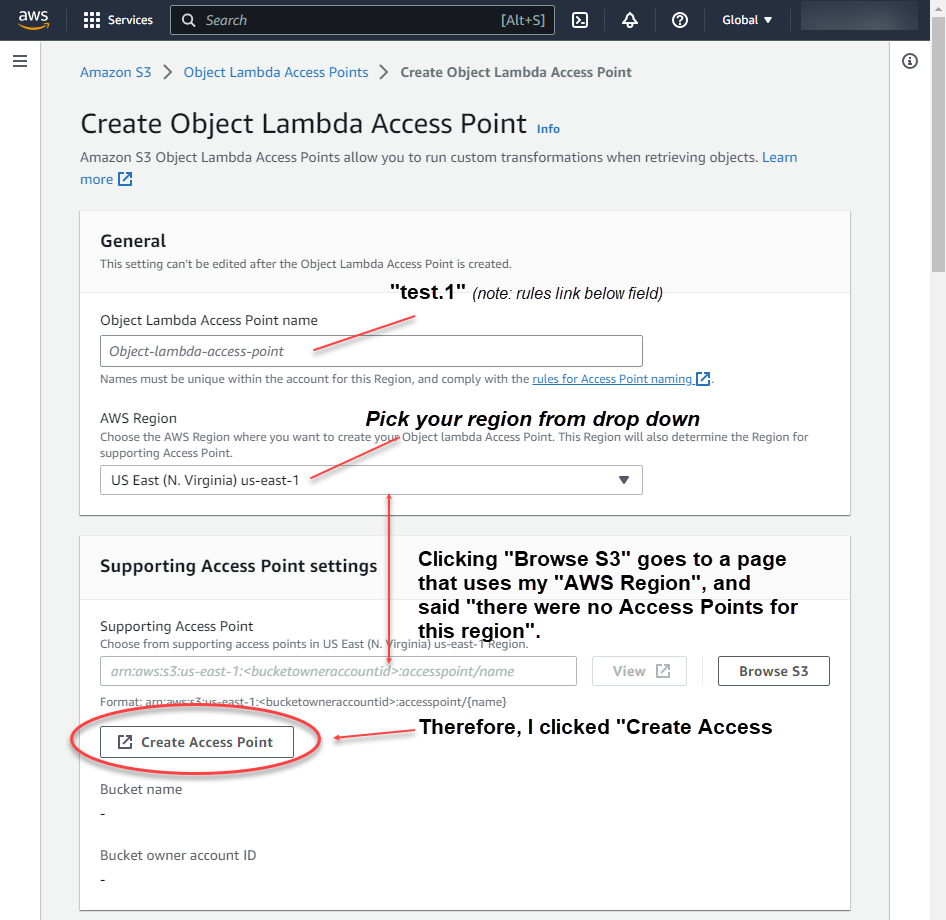
Image 4
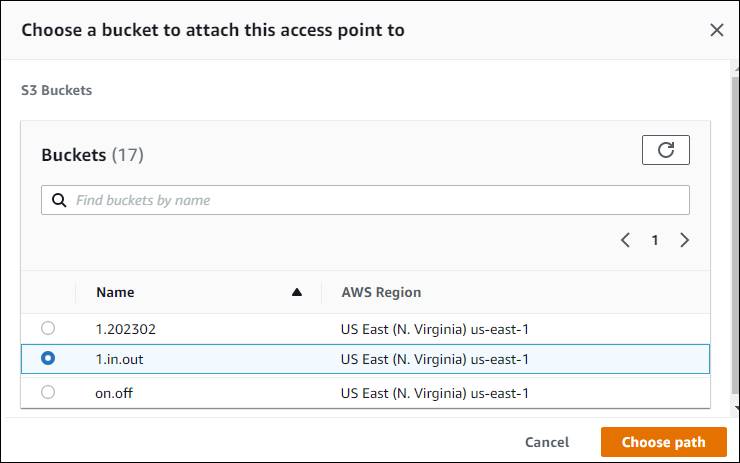
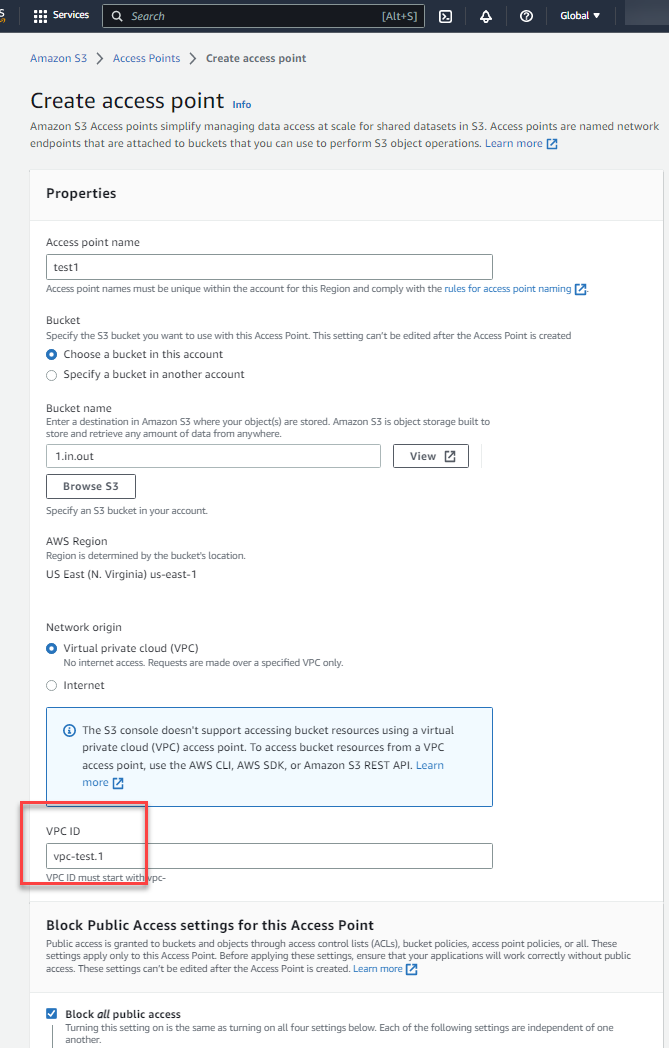
Image 5
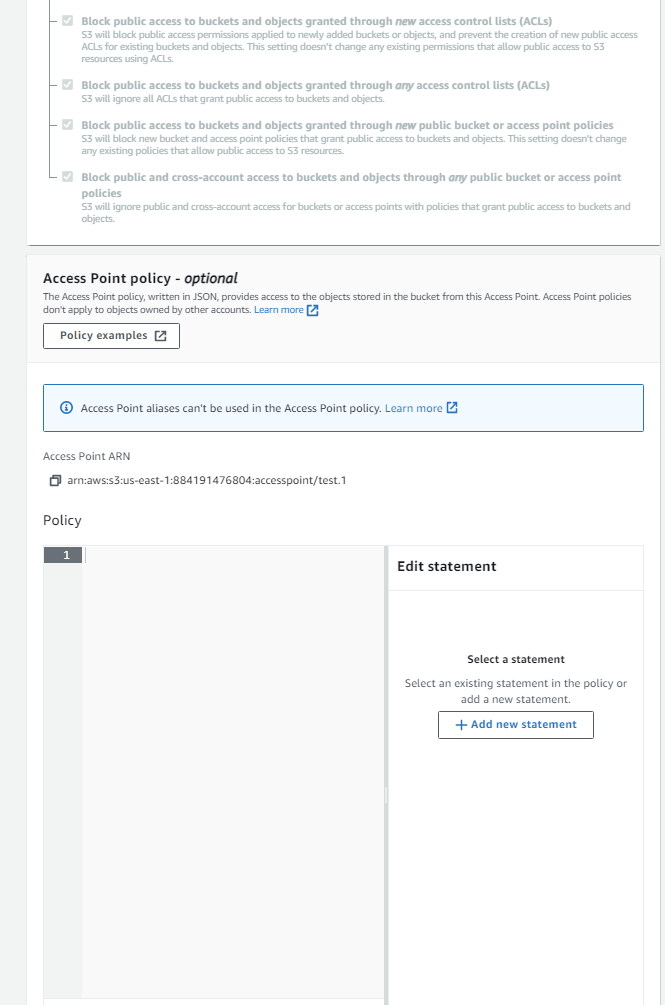
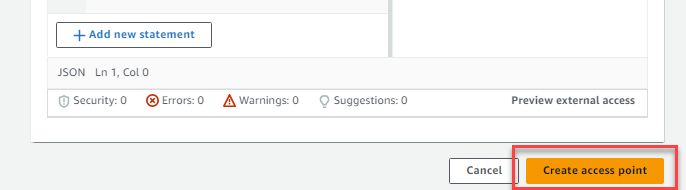
Image(s) 6
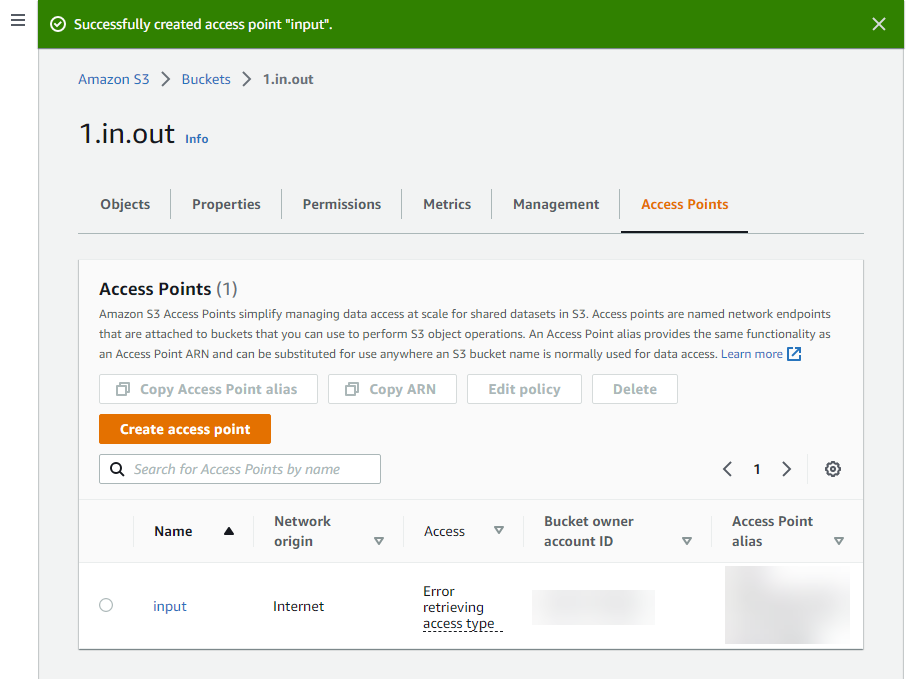
Image 7
- Give the function access to write to S3/output (Resources section of the UI)
Assuming that “Object Lambda Access Points” IS how you create a Lambda Function, how do I give it access to write to S3/Output (the other folder I created in Image 5)?
- Place
json file in S3/input and wait a few seconds for your transcript to show
up in output/
See below (Image 8), no updated/formatted transcript appears in output folder.
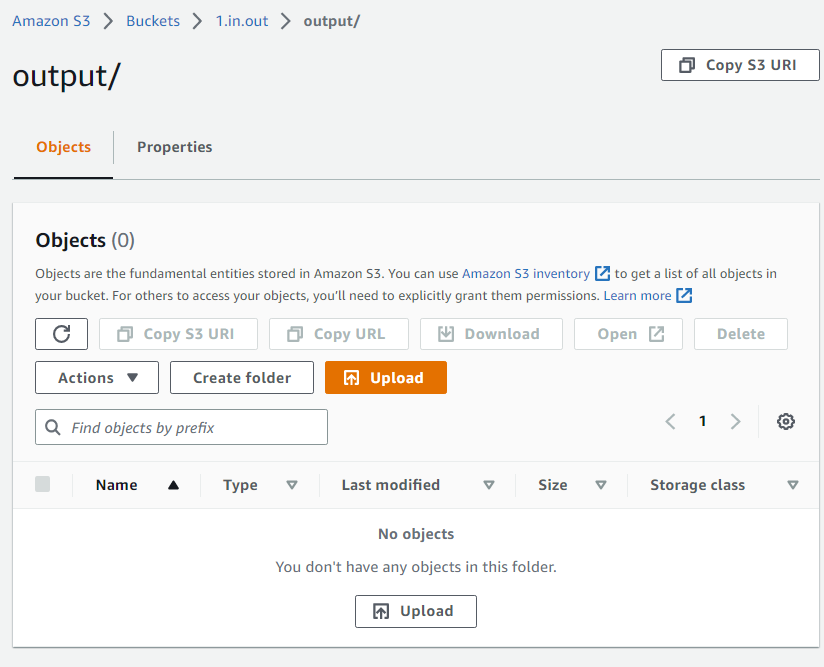
Image 8